 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInter-Stance: A Dyadic Multimodal Corpus for Conversational Stance Analysis
Apr 24, 2026Social interactions dominate our perceptions of the world and shape our daily behavior by attaching social meaning to acts as simple and spontaneous as gestures, facial expressions, voice, and speech. People mimic and otherwise respond to each other's postures, facial expressions, mannerisms, and other verbal and nonverbal behavior, and form appraisals or evaluations in the process. Yet, no publicly-available dataset includes multimodal recordings and self-report measures of multiple persons in social interaction. Dyadic recordings and annotation are lacking. We present a new data corpus of multimodal dyadic interaction (45 dyads, 90 persons) that includes synchronized multi-modality behavior (2D face video, 3D face geometry, thermal spectrum dynamics, voice and speech behavior, physiology (PPG, EDA, heart-rate, blood pressure, and respiration), and self-reported affect of all participants in a communicative interaction scenario. Two types of dyads are included: persons with shared past history and strangers. Annotations include social signals, agreement, disagreement, and neutral stance. With a potent emotion induction, these multimodal data will enable novel modeling of multimodal interpersonal behavior. We present extensive experiments to evaluate multimodal dyadic communication of dyads with and without interpersonal history, and their affect. This new database will make multimodal modeling of social interaction never possible before. The dataset includes 20TB of multimodal data to share with the research community.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
You Only Need One Stage: Novel-View Synthesis From A Single Blind Face Image
Mar 01, 2026We propose a novel one-stage method, NVB-Face, for generating consistent Novel-View images directly from a single Blind Face image. Existing approaches to novel-view synthesis for objects or faces typically require a high-resolution RGB image as input. When dealing with degraded images, the conventional pipeline follows a two-stage process: first restoring the image to high resolution, then synthesizing novel views from the restored result. However, this approach is highly dependent on the quality of the restored image, often leading to inaccuracies and inconsistencies in the final output. To address this limitation, we extract single-view features directly from the blind face image and introduce a feature manipulator that transforms these features into 3D-aware, multi-view latent representations. Leveraging the powerful generative capacity of a diffusion model, our framework synthesizes high-quality, consistent novel-view face images. Experimental results show that our method significantly outperforms traditional two-stage approaches in both consistency and fidelity.
Stabilizing Decentralized Federated Fine-Tuning via Topology-Aware Alternating LoRA
Jan 31, 2026Decentralized federated learning (DFL), a serverless variant of federated learning, poses unique challenges for parameter-efficient fine-tuning due to the factorized structure of low-rank adaptation (LoRA). Unlike linear parameters, decentralized aggregation of LoRA updates introduces topology-dependent cross terms that can destabilize training under dynamic communication graphs. We propose \texttt{TAD-LoRA}, a Topology-Aware Decentralized Low-Rank Adaptation framework that coordinates the updates and mixing of LoRA factors to control inter-client misalignment. We theoretically prove the convergence of \texttt{TAD-LoRA} under non-convex objectives, explicitly characterizing the trade-off between topology-induced cross-term error and block-coordinate representation bias governed by the switching interval of alternative training. Experiments under various communication conditions validate our analysis, showing that \texttt{TAD-LoRA} achieves robust performance across different communication scenarios, remaining competitive in strongly connected topologies and delivering clear gains under moderately and weakly connected topologies, with particularly strong results on the MNLI dataset.
Youtu-Parsing: Perception, Structuring and Recognition via High-Parallelism Decoding
Jan 28, 2026This paper presents Youtu-Parsing, an efficient and versatile document parsing model designed for high-performance content extraction. The architecture employs a native Vision Transformer (ViT) featuring a dynamic-resolution visual encoder to extract shared document features, coupled with a prompt-guided Youtu-LLM-2B language model for layout analysis and region-prompted decoding. Leveraging this decoupled and feature-reusable framework, we introduce a high-parallelism decoding strategy comprising two core components: token parallelism and query parallelism. The token parallelism strategy concurrently generates up to 64 candidate tokens per inference step, which are subsequently validated through a verification mechanism. This approach yields a 5--11x speedup over traditional autoregressive decoding and is particularly well-suited for highly structured scenarios, such as table recognition. To further exploit the advantages of region-prompted decoding, the query parallelism strategy enables simultaneous content prediction for multiple bounding boxes (up to five), providing an additional 2x acceleration while maintaining output quality equivalent to standard decoding. Youtu-Parsing encompasses a diverse range of document elements, including text, formulas, tables, charts, seals, and hierarchical structures. Furthermore, the model exhibits strong robustness when handling rare characters, multilingual text, and handwritten content. Extensive evaluations demonstrate that Youtu-Parsing achieves state-of-the-art (SOTA) performance on both the OmniDocBench and olmOCR-bench benchmarks. Overall, Youtu-Parsing demonstrates significant experimental value and practical utility for large-scale document intelligence applications.
Youtu-VL: Unleashing Visual Potential via Unified Vision-Language Supervision
Jan 27, 2026Despite the significant advancements represented by Vision-Language Models (VLMs), current architectures often exhibit limitations in retaining fine-grained visual information, leading to coarse-grained multimodal comprehension. We attribute this deficiency to a suboptimal training paradigm inherent in prevailing VLMs, which exhibits a text-dominant optimization bias by conceptualizing visual signals merely as passive conditional inputs rather than supervisory targets. To mitigate this, we introduce Youtu-VL, a framework leveraging the Vision-Language Unified Autoregressive Supervision (VLUAS) paradigm, which fundamentally shifts the optimization objective from ``vision-as-input'' to ``vision-as-target.'' By integrating visual tokens directly into the prediction stream, Youtu-VL applies unified autoregressive supervision to both visual details and linguistic content. Furthermore, we extend this paradigm to encompass vision-centric tasks, enabling a standard VLM to perform vision-centric tasks without task-specific additions. Extensive empirical evaluations demonstrate that Youtu-VL achieves competitive performance on both general multimodal tasks and vision-centric tasks, establishing a robust foundation for the development of comprehensive generalist visual agents.
Large Foundation Model for Ads Recommendation
Aug 20, 2025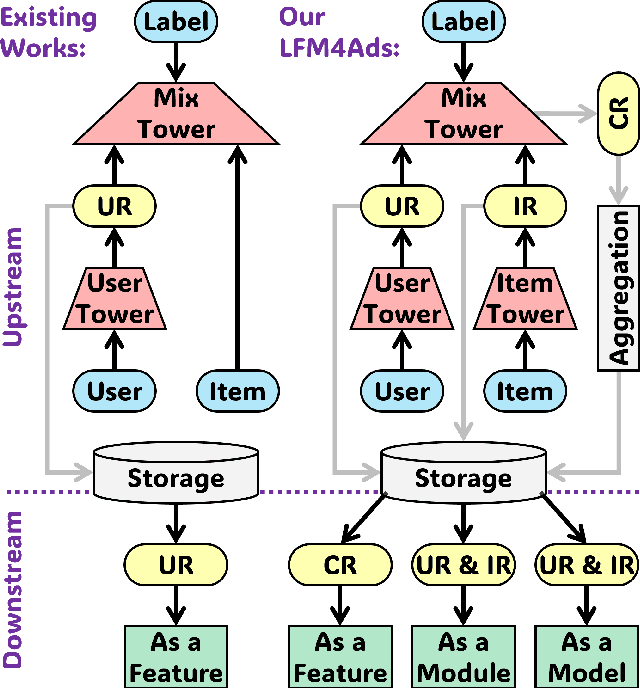
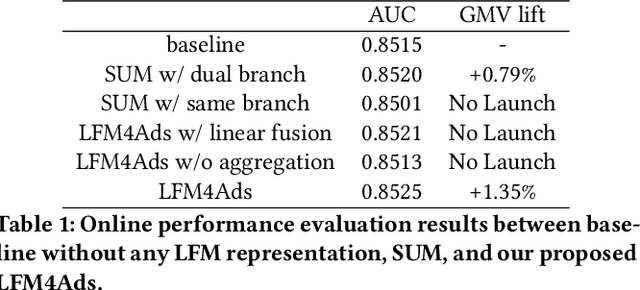
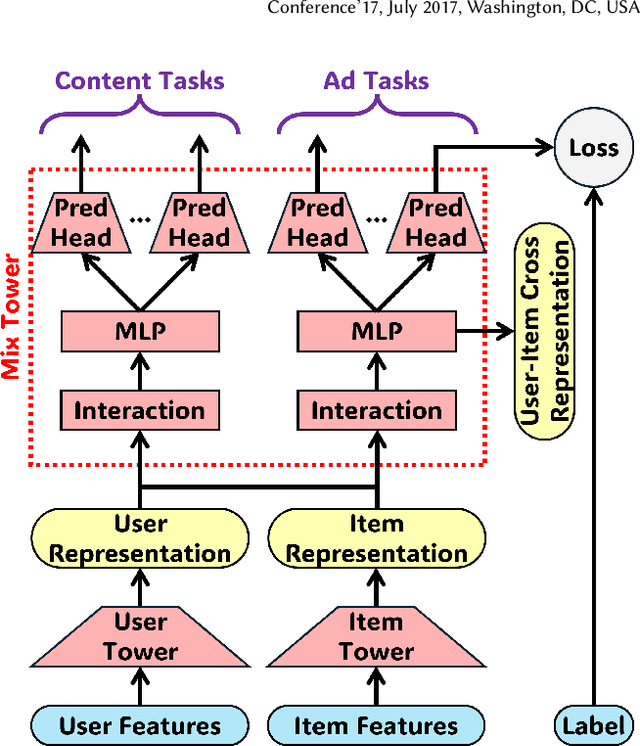
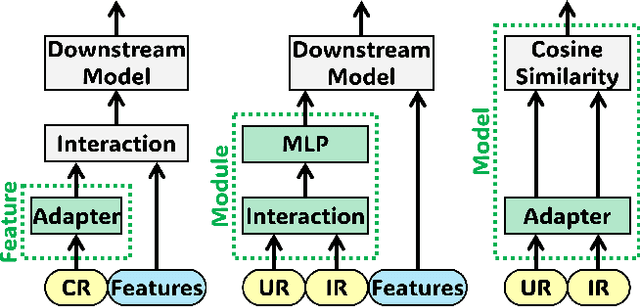
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models
Apr 22, 2025



We introduce PHYBench, a novel, high-quality benchmark designed for evaluating reasoning capabilities of large language models (LLMs) in physical contexts. PHYBench consists of 500 meticulously curated physics problems based on real-world physical scenarios, designed to assess the ability of models to understand and reason about realistic physical processes. Covering mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, the benchmark spans difficulty levels from high school exercises to undergraduate problems and Physics Olympiad challenges. Additionally, we propose the Expression Edit Distance (EED) Score, a novel evaluation metric based on the edit distance between mathematical expressions, which effectively captures differences in model reasoning processes and results beyond traditional binary scoring methods. We evaluate various LLMs on PHYBench and compare their performance with human experts. Our results reveal that even state-of-the-art reasoning models significantly lag behind human experts, highlighting their limitations and the need for improvement in complex physical reasoning scenarios. Our benchmark results and dataset are publicly available at https://phybench-official.github.io/phybench-demo/.
GAFusion: Adaptive Fusing LiDAR and Camera with Multiple Guidance for 3D Object Detection
Nov 01, 2024



Recent years have witnessed the remarkable progress of 3D multi-modality object detection methods based on the Bird's-Eye-View (BEV) perspective. However, most of them overlook the complementary interaction and guidance between LiDAR and camera. In this work, we propose a novel multi-modality 3D objection detection method, named GAFusion, with LiDAR-guided global interaction and adaptive fusion. Specifically, we introduce sparse depth guidance (SDG) and LiDAR occupancy guidance (LOG) to generate 3D features with sufficient depth information. In the following, LiDAR-guided adaptive fusion transformer (LGAFT) is developed to adaptively enhance the interaction of different modal BEV features from a global perspective. Meanwhile, additional downsampling with sparse height compression and multi-scale dual-path transformer (MSDPT) are designed to enlarge the receptive fields of different modal features. Finally, a temporal fusion module is introduced to aggregate features from previous frames. GAFusion achieves state-of-the-art 3D object detection results with 73.6$\%$ mAP and 74.9$\%$ NDS on the nuScenes test set.
The Diversity Bonus: Learning from Dissimilar Distributed Clients in Personalized Federated Learning
Jul 22, 2024



Personalized Federated Learning (PFL) is a commonly used framework that allows clients to collaboratively train their personalized models. PFL is particularly useful for handling situations where data from different clients are not independent and identically distributed (non-IID). Previous research in PFL implicitly assumes that clients can gain more benefits from those with similar data distributions. Correspondingly, methods such as personalized weight aggregation are developed to assign higher weights to similar clients during training. We pose a question: can a client benefit from other clients with dissimilar data distributions and if so, how? This question is particularly relevant in scenarios with a high degree of non-IID, where clients have widely different data distributions, and learning from only similar clients will lose knowledge from many other clients. We note that when dealing with clients with similar data distributions, methods such as personalized weight aggregation tend to enforce their models to be close in the parameter space. It is reasonable to conjecture that a client can benefit from dissimilar clients if we allow their models to depart from each other. Based on this idea, we propose DiversiFed which allows each client to learn from clients with diversified data distribution in personalized federated learning. DiversiFed pushes personalized models of clients with dissimilar data distributions apart in the parameter space while pulling together those with similar distributions. In addition, to achieve the above effect without using prior knowledge of data distribution, we design a loss function that leverages the model similarity to determine the degree of attraction and repulsion between any two models. Experiments on several datasets show that DiversiFed can benefit from dissimilar clients and thus outperform the state-of-the-art methods.